August 6, 2020
Image recognition is a popular topic in machine learning and frequently appears in everyday life, unbeknownst to the untrained eye. We see it in law-enforcement cameras, self-driving cars, phones, and more. Consequently, ethical issues have risen where people’s privacy comes into question. Regardless, image recognition can be applied into many unique areas.
Inspired from PBS shows where historians validate the legitimacy of paintings or artwork, could someone (me), spot foregies and real paintings with the help of image recognition? Historians often use the style of brush strokes, chemical composition of paints, signatures, and carbon dating to validate pieces of art. Theoretically, with the highest resolution attainable, a computer can see the brush strokes and use that as a form of classification whether a painting belongs to a certain artist or not. This is the first of many issues with this project: space. I doubt my computer can house a training dataset of reasonable size, where the resolution allows for close ups of brush strokes. Another issue I ran into, is that Google recently changed something that does not allow the Python scripts I have for mass image downloading. These issues are definitely fixable, but probably something I’ll need help with in obtaining high resolution images of verified art.
After dealing with these issues I decided on a variation of the original idea, where I classify the style of paintings. By style I am referring to a painting’s origin. For example, ancient Italian, Japanese, Spanish, German, paintings all possess different styles. Therefore, the planned project is for someone to input an unfamiliar painting and have the model output its origin. I predict that the model would work well with very few classes, the classes are the country of origin. The model might distinguish between Japanese and Italian art well, but maybe not Japanese and Chinese. The persistent issue is obtaining the data without a mass downloader or collections of art I can download with one click, so I am gonna have to deal with a fairly small set of images.
The first attempt is to see if a model can distinguish between two forms of art, Japanese and Italian. If a model performs terrible here, then a model with more classes is probably gonna be even worse. For reference, there are images below for the Japanese and Italian art style based off of Google’s image search.


Some basic observations are that the Japanese paintings have plain backgrounds while the entirety of the Italian paintings are completely filled and painted. Once the images are given labels and are separated into training and testing sets, I can construct the convolutional neural network (CNN). Unlike other neural networks, the CNN is a little bit more specific in terms of its architecture. The first layer will do feature mapping while the last layer typically uses softmax function for multiclass classification. In my first data set where I am attempting to classify Japanese and Italian art, a logistic function might be better since I have binary classes. Since the CNN needs a convolutional layer to begin with, I am using the Conv2D layer from the keras packaged where I have the Maxsoftpooling2D layer between another convolution later. The pooling layer is tasked with reducing the size of the images while preserving their important characteristics. Along with additional layers and ReLu functions, the CNN is on my github (insert link) where you can take a closer look.
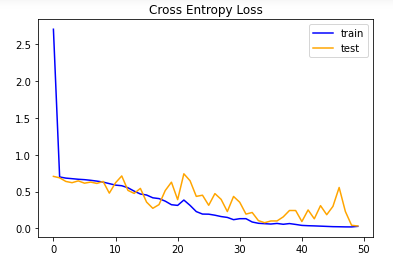
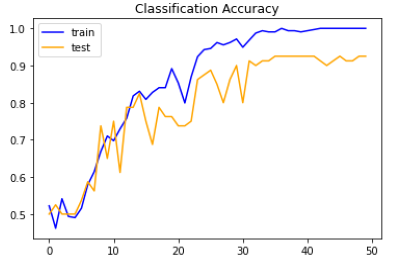
After running the model, with about 180 training for each class, I received an accuracy of about 92.5% with validation data. That's a very good start to the mode, but it is only with 2 classes. The accuracy plots are below. It does not appear that the model is overfitting or underfitting. Overfitting happens when the model too strongly predicts the training data and can't be applied to new data and underfitting suggests the model does not fit, in other words, does not predict, the (training) data very well. Underfitting is when the model performs poorly for both the training and testing data, which could be caused my lack of training data or a incorrect/bad model.
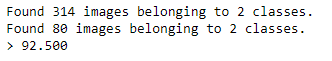
I did eventually find a way to mass download images off of Google, but it still comes with its challenges. Since I am downloading the paintings off of Google Images, I have to trust that Google gives me legitimate paintings when I search something like, “French Renaissance Paintings.” And in conclusion, Google is a liar. The downloading worked better than dragging and dropping images by hand, but when I was checking my folders, there’s pictures of Anthony Hopkins and other peculiar outliers that I had to delete. Other downloads that would threaten training included actual photographs or images with text boxes over them.
So now, for the new model I have an increased data set for each country of origin, which means a larger training set. However, I added two additional classes with a total of four: Japanese, Italian, German, and French. German art looks pretty different from Italian and Japanese, but French art looks like a combination of the German and Italian art which poses difficulties. At this point, it looks like the model is gonna have some difficulties. The French (left) and German (right) paintings can be seen below.


After training, testing, and validating, my multi-classifier handeled the paintings fairly well, but the addition of more classes made it difficult. I recieved an accuracy of 73.33% I think the model would be vastly improved with legitimate training data from peer reviewed sources. Having to trust Google Images is not ideal, and I do not have confirmation if the paintings are what I actaully searched. Another thing, would to feed the model specific features of each type of painting. I am not art historian, but knowing the specific characteristics of each class of painting, and then incorporating close ups of those features into the training should help the overall performance of the model.

Somethings that had to be changed included the loss and optimization functions when using data with more than 2 labels. For example, in the Japanese-Italian model I was able to use a binary loss function while I adjusted the other model to use a sparse loss function with an Adam optimizer. Overall, I am kind of impressed with the model, especially with how similar some of the paitings are. Going back through some of the data and checking mistakes, it appears that the main source of errors came from the French and Italian paintings. Not too surprisng based off how they look.